





所有平台仅提供服务对接功能,所载文章、数据仅供参考,股市有风险,投资需谨慎,用户需独立做出投资决策,风险自担!

时间:2021-04-16 16:49:08来源:砍柴网
Serverless容器的服务发现
2020年9月,UCloud 优刻得上线了Serverless容器产品Cube,它具备了虚拟机级别的安全隔离、轻量化的系统占用、秒级的启动速度,高度自动化的弹性伸缩,以及简洁明了的易用性。结合虚拟节点技术(Virtual Kubelet),Cube可以和UCloud 优刻得容器托管产品UK8S无缝对接,极大地丰富了Kubernetes集群的弹性能力。如下图所示,Virtual Node作为一个虚拟Node在Kubernetes集群中,每个Cube实例被视为VK节点上的一个Pod。
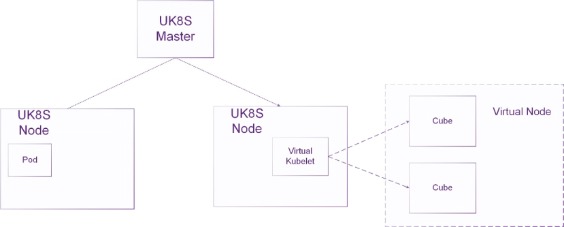
然而,Virtual Kubelet仅仅实现了集群中Cube实例的弹性伸缩。要使得Cube实例正式成为K8s集群大家庭的一员,运行在Cube中的应用需要能利用K8s的服务发现能力,即访问Service地址。
为什么不是kube-proxy?
众所周知, kube-proxy为K8s实现了service流量负载均衡。kube-proxy不断感知K8s内Service和Endpoints地址的对应关系及其变化,生成ServiceIP的流量转发规则。它提供了三种转发实现机制:userspace, iptables和ipvs, 其中userspace由于较高的性能代价已不再被使用。
然而,我们发现,直接把kube-proxy部署在Cube虚拟机内部并不合适,有如下原因:
1 、kube-proxy采用go语言开发,编译产生的目标文件体积庞大。以K8s v1.19.5 linux环境为例,经strip过的kube-proxy ELF可执行文件大小为37MB。对于普通K8s环境来说,这个体积可以忽略不计;但对于Serverless产品来说,为了保证秒起轻量级虚拟机,虚拟机操作系统和镜像需要高度裁剪,寸土寸金,我们想要一个部署体积不超过10MB的proxy控制程序。
2 、kube-proxy的运行性能问题。同样由于使用go语言开发,相对于C/C++和Rust等无gc、具备精细控制底层资源能力的高级语言来说,要付出更多的性能代价。Cube通常存在较细粒度的资源交付配额,例如0.5C 500MiB,我们不希望kube-proxy这类辅助组件喧宾夺主。
3 、ipvs的问题。在eBPF被广为周知之前,ipvs被认为是最合理的K8s service转发面实现。iptables因为扩展性问题被鞭尸已久,ipvs却能随着services和endpoints规模增大依然保持稳定的转发能力和较低的规则刷新间隔。
但事实是,ipvs并不完美,甚至存在严重的问题。
例如,同样实现nat , iptables是在PREROUTING或者OUTPUT完成DNAT;而ipvs需要经历INPUT和OUTPUT,链路更长。因此,较少svc和ep数量下的service ip压测场景下,无论是带宽还是短连接请求延迟,ipvs都会获得全场最低分。此外,conn_reuse_mode的参数为1导致的滚动发布时服务访问失败的问题至今(2021年4月)也解决的不太干净。
4 、iptables的问题。扩展差,更新慢,O(n)时间复杂度的规则查找(这几句话背不出来是找不到一份K8s相关的工作的), 同样的问题还会出现在基于iptables实现的NetworkPolicy上。1.6.2以下iptables甚至不支持full_random端口选择,导致SNAT的性能在高并发短连接的业务场景下雪上加霜。
eBPF能为容器网络带来什么?
eBPF近年来被视为linux的革命性技术,它允许开发者在linux的内核里动态实时地加载运行自己编写的沙盒程序,无需更改内核源码或者加载内核模块。同时,用户态的程序可以通过bpf(2)系统调用和bpf map结构与内核中的eBPF程序实时交换数据,如下图所示。
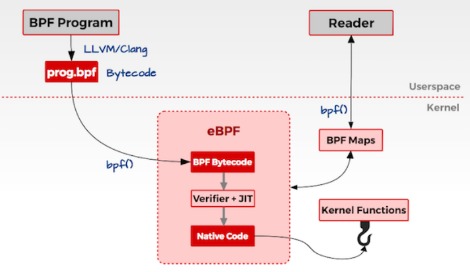
编写好的eBPF程序在内核中以事件触发的模式运行,这些事件可以是系统调用入出口,网络收发包的关键路径点(xdp, tc, qdisc, socket),内核函数入出口kprobes/kretprobes和用户态函数入出口uprobes/uretprobes等。加载到网络收发路径的hook点的eBPF程序通常用于控制和修改网络报文, 来实现负载均衡,安全策略和监控观测。
cilium的出现使得eBPF正式进入K8s的视野,并正在深刻地改变k8s的网络,安全,负载均衡,可观测性等领域。 从1.6开始,cilium可以100%替换kube-proxy,真正通过eBPF实现了kube-proxy的全部转发功能。 让我们首先考察一下ClusterIP(东西流量)的实现。
ClusterIP的实现
无论对于TCP还是UDP来说,客户端访问ClusterIP只需要实现针对ClusterIP的DNAT,把Frontend与对应的Backends地址记录在eBPF map中,这个表的内容即为后面执行DNAT的依据。那这个DNAT在什么环节实现呢?
对于一般环境,DNAT操作可以发生在tc egress,同时在tc ingress
中对回程的流量进行反向操作,即将源地址由真实的PodIP改成ClusterIP, 此外完成NAT后需要重新计算IP和TCP头部的checksum。
如果是支持cgroup2的linux环境,使用cgroup2的sockaddr hook点进行DNAT.cgroup2为一些需要引用L4地址的socket系统调用,如connect(2), sendmsg(2), recvmsg(2)提供了一个BPF拦截层(BPF_PROG_TYPE_CGROUP_SOCK_ADDR)。这些BPF程序可以在packet生成之前完成对目的地址的修改,如下图所示。
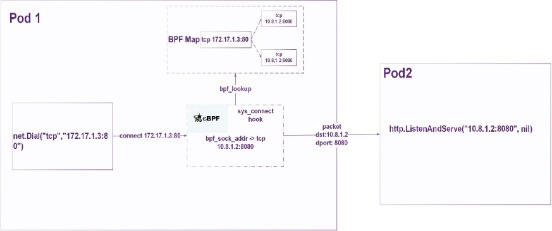
对于tcp和有连接的udp的流量(即针对udp fd调用过connect(2))来说, 只需要做一次正向转换,即利用bpf程序,将出向流量的目的地址改成Pod的地址。这种场景下,负载均衡是最高效的,因为开销一次性的,作用效果则持续贯穿整个通信流的生命周期。
而对于无连接的udp流量,还需要做一次反向转换,即将来自Pod的入向流量做一个SNAT,将源地址改回ClusterIP。如果缺了这一步操作,基于recvmsg的UDP应用会无法收到来自ClusterIP的消息,因为socket的对端地址被改写成了Pod的地址。流量示意图如下所示。
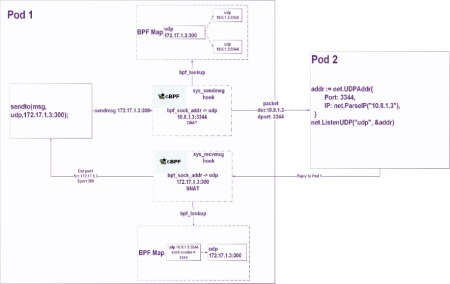
综述,这是一种用户无感知的地址转换。用户认为自己连接的地址是Service, 但实际的tcp连接直接指向Pod。一个能说明问题的对比是,当你使用kube-proxy的时候,在Pod中进行tcpdump时,你能发现目的地址依然是ClusterIP,因为ipvs或者iptables规则在host上;当你使用cilium时,在Pod中进行tcpdump,你已经能发现目的地址是Backend Pod.NAT不需要借助conntrack就能完成,相对于ipvs和iptables来说,转发路径减少,性能更优。而对比刚才提到的tc-bpf,它更轻量,无需重新计算checksum。
Cube的Service服务发现
Cube为每个需要开启ClusterIP访问功能的Serverless容器组启动了一个叫cproxy的agent程序来实现kube-proxy的核心功能。由于Cube的轻量级虚拟机镜像使用较高版本的linux内核,cproxy采用了上述cgroup2 socket hook的方式进行ClusterIP转发。cproxy使用Rust开发,编译后的目标文件只有不到10MiB。运行开销相比kube-proxy也有不小优势。部署结构如下所示。
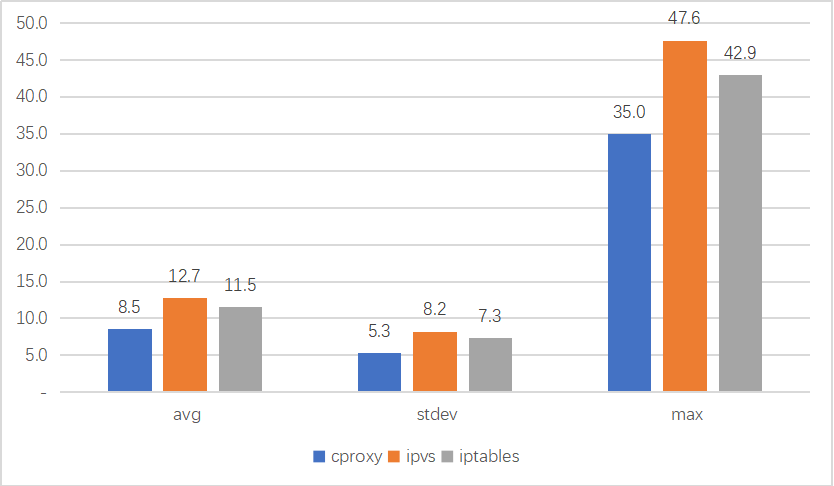
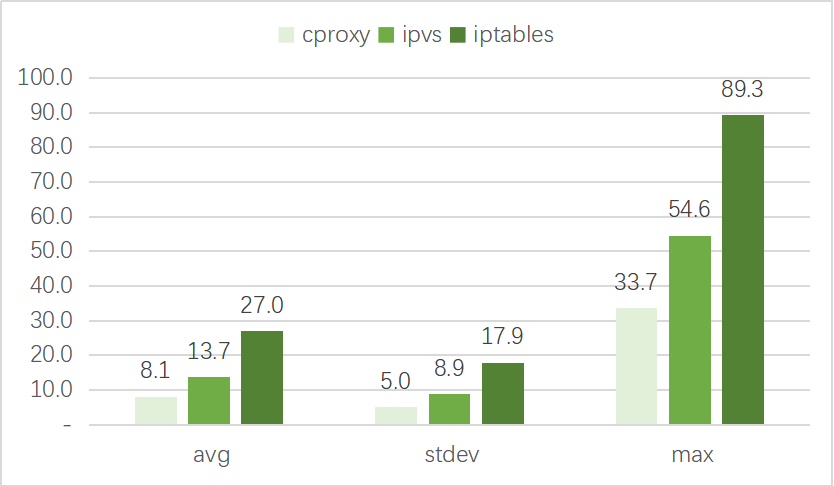
以下是一些测试情况对比。我们使用wrk对ClusterIP进行2000并发HTTP短连接测试,分别比较svc数量为10和svc数量为5000,观察请求耗时情况(单位ms)。
结论是cproxy无论在svc数量较少和较多的情况下,都拥有最好的性能;ipvs在svc数量较大的情况下性能远好于iptables,但在svc数量较小的情况下,性能不如iptables。
svc数量=10
svc数量=5000
后续我们会继续完善基于eBPF实现LoadBalancer(南北流量)转发,以及基于eBPF的网络访问策略(NetworkPolicy)。
UCloud 优刻得容器产品拥抱eBPF
eBPF正在改变云原生生态, 未来UCloud 优刻得容器云产品 UK8S与Serverless容器产品Cube将紧密结合业内最新进展,挖掘eBPF在网络,负载均衡,监控等领域的应用,为用户提供更好的观测、定位和调优能力。
声明:文章仅代表原作者观点,不代表本站立场;如有侵权、违规,可直接反馈本站,我们将会作修改或删除处理。


图文推荐
2021-04-16 16:49:08
2021-04-16 13:49:57
2021-04-16 12:49:47
2021-04-16 12:49:06
2021-04-16 11:49:50
2021-04-16 10:49:19
热点排行
精彩文章

2021-04-16 10:49:32
2021-04-16 09:49:17

2021-04-15 18:49:46
2021-04-15 17:50:21

2021-04-14 18:50:05

2021-04-14 15:49:59
热门推荐
