





所有平台仅提供服务对接功能,所载文章、数据仅供参考,股市有风险,投资需谨慎,用户需独立做出投资决策,风险自担!

时间:2021-03-21 09:49:54来源:贝壳财经
3月20日,北京智源人工智能研究院发布了包括中文、多模态、认知、蛋白质预测在内的超大规模智能模型“悟道1.0”。智源研究院院长,北京大学信息科学技术学院教授黄铁军表示,近年来人工智能的发展,已经从“大炼模型”逐步迈向了“炼大模型”阶段。
“过去五年多,全球研究人工智能研究者最重要的就是训练各种各样的模型,这几年有一点‘千村万户炼模型’的状态。不论大小公司还是学校,都是拿一个开源的框架,收集一批数据,然后拿着这个模型去解决问题。虽然这是可以成功的,但作为一个现代化产业,近年来人工智能的发展应该从家家户户‘大炼模型’的状态逐渐变为把资源汇聚起来,训练超大规模模型的阶段,通过设计先进的算法,整合尽可能多的数据,汇聚大量算力,集约化地训练大模型,供大量企业使用,这是必然趋势。”黄铁军表示。
智源研究院学术副院长唐杰介绍,“悟道1.0”先期启动了4个大模型的研发,包括面向中文的预训练语言模型、首个公开的中文通用图文多模态预训练模型、我国首个具有认知能力的超大规模预训练模型以及超大规模蛋白质序列预测预训练模型。
新京报贝壳财经记者了解到,以其中文通用图文多模态预训练模型为例,该模型参数量达10亿,基于从公开来源收集到的5000万个图文进行训练,是首个公开的中文通用图文多模态预训练模型。目前,该模型已经落地了可以为用户上传照片配文,以及利用图片和歌词相关性为用户上传照片搭配音乐的小程序及应用。
声明:文章仅代表原作者观点,不代表本站立场;如有侵权、违规,可直接反馈本站,我们将会作修改或删除处理。


图文推荐
2021-03-21 08:49:15

2021-03-20 19:50:14

2021-03-20 17:50:03
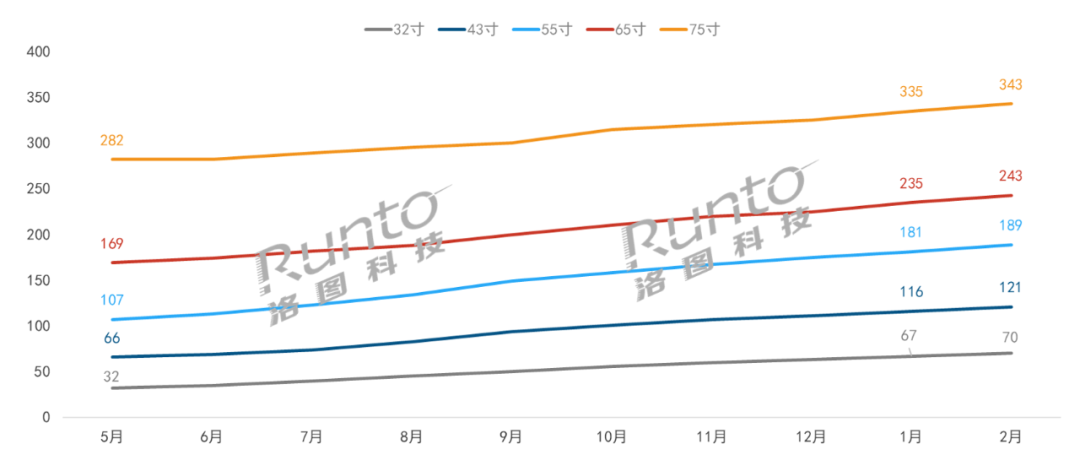
2021-03-20 17:49:18
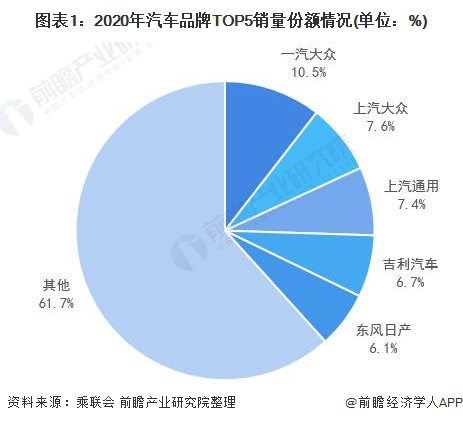
2021-03-20 13:49:25
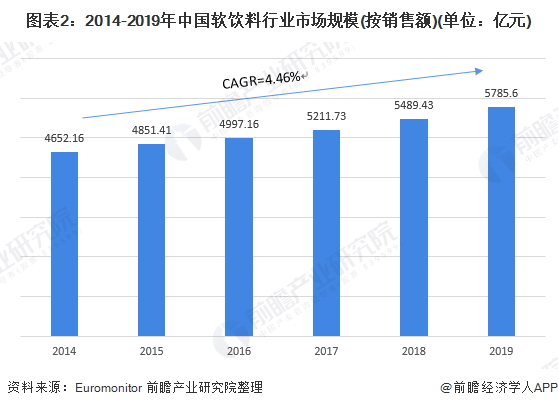
2021-03-20 09:49:14
热点排行
精彩文章

2021-03-20 19:49:45

2021-03-20 18:50:22

2021-03-20 18:49:37

2021-03-20 17:50:18

2021-03-20 17:49:34

2021-03-20 16:49:36
热门推荐
